
With the advent of AI coding agents, multi-thousand-line Pull Requests are becoming the new normal. The models are churning out massive amounts of code, and keeping up is getting exponentially harder. Because I don’t have a granular understanding of every single line being merged, I’m finding it increasingly difficult to generate accurate mental models of the system’s new features.
For humans, mental models are everything. We need context and an adequate knowledge of the system to reason about new architecture, confidently add features, or know exactly where to look when a production bug inevitably surfaces.
Basically, the more intelligent and adaptive the AI becomes at writing code, the less able I am to truly understand the system, make sense of its state, or form the judgment necessary to catch the shortcomings in the AI-generated code itself!
The Rise of Cognitive Debt
In software engineering, we are intimately familiar with technical debt. But with the advent of AI agents, we are now dealing with “cognitive debt.” I won’t claim to have coined the term, a 2025 MIT Media Lab study measured the “accumulation of cognitive debt” in people who leaned on an LLM to write essays, but it captures exactly what I feel reviewing AI-generated code.
This debt compounds every time you don’t write the code yourself, or aren’t deeply involved in understanding why it was written the way it was. I’ve been thinking about this a lot lately: if we aren’t writing code by hand anymore, how do we keep our technical skills sharp?
Turns out, cognitive debt from automation isn’t a new problem. We’ve been researching it for over four decades. Lisanne Bainbridge wrote a seminal paper called “Ironies of Automation” back in 1983. AI didn’t create this problem; it just strapped a rocket to it.
I recently watched a great InfoQ talk by J. Paul Reed on the “Ironies of Automation and AI,” and a few key points perfectly describe the reality of managing complex, automated systems today:
- Skill Degradation: Manual skills deteriorate when they are not used. You automate a complex deployment, and during the next incident, you can’t remember the baseline command arguments.
- The Novelty Trap: Generating “new strategies” requires an adequate knowledge of the system. Basically: no mental model, no novel fixes!
- The Speed/Correctness Tradeoff: You cannot assert absolute correctness and maintain high speed simultaneously (echoing Erik Hollnagel’s ETTO principle: you can never maximize efficiency and thoroughness at the same time).
- Camouflaged State: Automation can easily hide the current state of the system from operators.
- Opaque Logic: Tracing algorithmic decision trees is difficult, and with AI, it can be nearly impossible.
Adding to this, Mica Endsley notes a newer irony specific to AI: The more capable the AI, the poorer people’s self-adaptive behaviors for compensating for its shortcomings.
You Cannot Outsource Understanding
“Well, the first rule is that you can’t really know anything if you just remember isolated facts and try to bang ‘em back. If the facts don’t hang together on a latticework of theory, you don’t have them in a usable form. You’ve got to have mental models in your head.” ― Charlie Munger
So, how do we reduce this compounding cognitive debt? We have to actively build robust mental models to widen our understanding of the systems we manage.
The AI doesn’t relieve you of the mental model, you need it precisely to know when the AI is wrong.
It reminds me of a brilliant point Andrej Karpathy made a few months ago: You can outsource your thinking, but you cannot outsource understanding.
Mark Russinovich echoed a very similar sentiment at a recent Microsoft internal event. To paraphrase him: If you want to be productive, use AI. But if you want to learn, do things the old way using your brain.
Fighting Back with Visualization
We need to spend time with the system, use it, and read the code. But staring at a 5,000-line diff in GitHub isn’t an effective way for a human brain to build a mental model.
To counter this, I created a custom skill that generates a rich visualization of a Pull Request.
The rationale behind this skill was heavily inspired by a recent post from the Claude Code team regarding the “unreasonable effectiveness of HTML.”
Markdown is a great format for humans to write, but it has limitations when it comes to consuming complex information. It lacks the ability to convey dense architectural changes visually (though Mermaid diagrams are certainly helping).
HTML, on the other hand, is a phenomenal format for humans to consume. With embedded CSS and JS, it can be entirely self-sustaining, interactive, and visually dense. The problem has always been that complex HTML/JS is tedious for humans to write by hand just to visualize a PR.
But this is exactly where coding agents excel.
My new skill bridges this gap. It feeds the multi-thousand-line PR to an agent and tasks it with generating a comprehensive, interactive HTML visualization of the changes. Instead of drowning in line-by-line diffs, I get a visual map of the architecture and logic flow, helping me rebuild that crucial latticework of theory in my head before I approve the merge.
Here is a sample visualization of a PR generated by the skill:
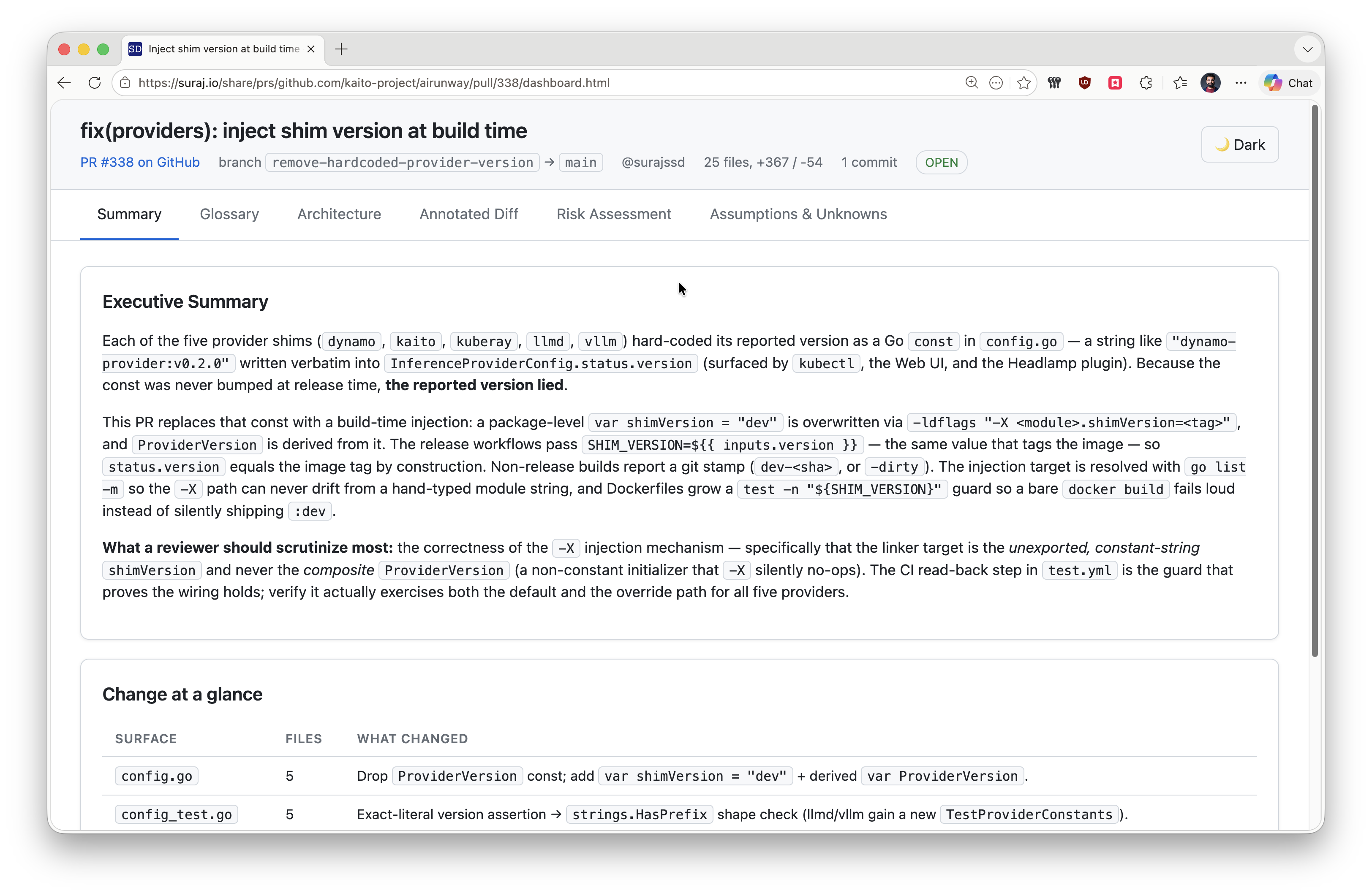
Generating visual dashboards is the first step in rebuilding that mental scaffolding. If you want to automate this process yourself, here is how the skill operates under the hood.
How the Dashboard Works
If you are curious about the mechanics behind the visualization above, the workflow is straightforward. pr-review-dashboard turns a checked-out PR into a single self-contained interactive HTML dashboard (diagrams + annotated diffs + risk table) instead of a markdown summary. It runs a 7-step playbook: detect the default branch, sanity-check you’re on a feature branch, gather the diff (three-dot) and resolve the GitHub PR via a fallback ladder, then fill a bundled dashboard_template.html across six tabs (Summary, Glossary, Architecture, Diff, Risk, Unknowns). Its core ethos is “visualization is the point”, 3–6 diagrams, defaulting to HTML/CSS box-and-arrow primitives and reserving mermaid only for sequence/state/class diagrams. Strict grounding rules require citing file:line and quarantining all uncertainty in the Unknowns tab.
Instead of fighting the agent, I am using its immense context window to generate the exact artifact my human brain needs to do its job.
How to Use the Skill
Check out the PR you want to visualize, and run the following command in your agent terminal:
/pr-review-dashboard
Conclusion
The irony of AI coding agents is that to use them safely, you actually have to understand your system better than before.
Automation will continue to push the boundaries of efficiency, but we can never maximize efficiency and thoroughness at the same time. The AI does not relieve you of the responsibility of the mental model, you need it precisely to know when the AI is hallucinating a fix or introducing a subtle architectural flaw.
Embrace the agents to write the boilerplate, write the tests, and even write the HTML dashboards. But protect your mental models at all costs. You can outsource your coding, but you cannot outsource your understanding.